به کارگیری هوش مصنوعی در حوزههای مختلف از چند سال قبل شروع شده است و اینطور نیست که هوش مصنوعی هنوز یک امر تفننی و تفریحی باشد یا فقط سوالات سادهی ما را پاسخ دهد. اگرچه هوش مصنوعی فعلی هنوز هم با کاستیهایی روبروست، اما با همین الگوریتمها نیز اکتشافات بزرگی اتفاق افتاده است. پس نیازی نیست که صبر کنیم تا یک تکنولوژی به بلوغ (maturity) خود برسد و سپس ما از آن استفادههای واقعی داشته باشیم. لازم نیست هوش مصنوعی حتما تواناییهای یک انسان را داشته باشد یا به چیزی تحت عنوان خودآگاهی واقعی رسیده باشد که ما بتوانیم به کاربردهای آن برسیم. تنها کافیست که این الگوریتمها در یک سری جنبهها و تواناییها از ما بهتر باشند و کاستیهای ما را بپوشانند. آنوقت است که ما با همان برتریها، میتوانیم کارهایی بکنیم که پیشتر قادر به آن نبودهایم. به عنوان مثال، در توانایی تحلیل حجم عظیم داده، ما انسانها خیلی راحت، مسابقه را به این مدلها میبازیم.
اما در کجا ما چنین حجمی از داده را سراغ داریم؟
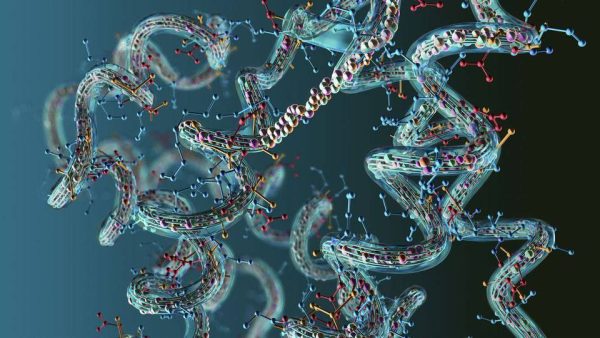
مثلا زیست شناسی. همهی ما پروتئینها را به عنوان اجزای مهم حیات میشناسیم. تمام واکنشهای شیمیایی درون بدن ما و دیگر موجودات زنده به پروتئینها و به خصوص ساختار آنها وابسته است. تمامی پروتئینهایی که ما میشناسیم، تنها از ۲۰ نوع آمینواسید تشکیل شده اند. آمینواسیدهای مختلف به ترتیب و تعداد متفاوت به صورت یک زنجیر مستقیم به یکدیگر متصل میشوند و سپس این زنجیر تحت تاثیر نیروهای مختلف بین مولکولی و درون مولکولی، از قسمتهای مختلف تا شده و یک ساختار سه بعدی را میسازند که این ساختار سه بعدی پیچیده همان پروتئین است. همین ساختار سه بعدی به پروتئین خواص گوناگون میدهد و مشخص میکند که این پروتئین چه واکنشهایی ایجاد میکند. هر واکنشی نیز خروجیهای مختلفی را به همراه دارد. پس ما نیاز داریم بدانیم که این ساختار سه بعدی چگونه ایجاد میشود و باید بتوانیم این ساختار را پیشبینی کنیم. مثلا بدانیم که اگر این آمینواسیدها به این ترتیب به یکدیگر متصل شوند، خروجی آن چه پروتئینی با چه ساختاری خواهد بود و آن ساختار، چه واکنش زیستی را با خود به همراه خواهد داشت.
این سوالی بود که محققان گوناگون از دههی ۱۹۷۰ میلادی بدین سو سعی در یافتن پاسخی برای آن بوده اند.
اما این تلاشها تا همین چند سال قبل، چندان موفقیت آمیز نبود. چون حجم دادههای موجود بسیار بزرگ بود و مغز ما و حتی الگوریتمهای معمول کامپیوتری، قادر به تحلیل این حجم عظیم از داده نبودند. برای درک حجم این دادهها، خوب است بدانیم که تعداد پروتئینهایی که دانشمندان تاکنون کشف کردهاند چیزی حدود ۲۰۰ میلیون پروتئین است.
در سال ۲۰۲۰، دو دانشمند بخش دیپ مایند گوگل به نامهای دمیس هاسابیس و جان جامپر، یک مدل هوش مصنوعی به نام AlphaFold2 را توسعه دادند که براساس دادههای پروتئینها، آموزش دیده بود. آلفافولد۲ موفق شد با دقت بسیار بالایی، ساختار تقریبا تمامی ۲۰۰ میلیون پروتئین شناخته شده را پیشبینی کند. تاکنون بیش از دو میلیون محقق از سراسر دنیا در پژوهشهای خو از آلفافولد۲ استفاده کرده اند. حالا دانشمندان به کمک هوش مصنوعی میتوانند چیزی مثل مقاومت آنتی بیوتیکی را بهتر درک کنند و یا اینکه میتوانند پروتئین جدیدی بسازند که ویژگیهای جدیدی مثل قابلیت تجزیهی پلاستیکها را به ما بدهد. حالا ما با کمک هوش مصنوعی، خودمان میتوانیم پروتئین بسازیم. از بابت توسعهی آلفافولد۲، این دو دانشمند موفق شدند نوبل شیمی سال ۲۰۲۴ را از آن خود کنند.
– ابا اباد